Предварительные замечания
Предлагаемая методика использования xMarkup, mystem и MS Access позволяет выполнять следующее:
- автоматическое разделение текста на абзацы, абзацев – на предложения, а предложений – на слова (словоупотребления);
- автоматическое получение частотного списка словоупотреблений;
- автоматизированная лемматизация словоупотреблений (получение списков <словоупотребление> – <лексема><лексема> – <часть речи>);
- автоматическое получение частотного списка лексем;
- автоматизируемое присвоение семантических категорий лексемам или выделение лексико-семантических вариантов одной лексемы;
- автоматическое построение картотек и конкордансов для словоупотреблений, лексем, слов одной части речи или семантической категории;
- автоматизированное выделение грамматически связанных сочетаний слов, расположенных как контактно, так и дистантно.
Определение автоматический означает, что программа реализует указанную функцию без участия человека, определение автоматизированный подразумевает большую или меньшую степень ручной работы, а автоматизируемый указывает на то, что эта функция может быть автоматизирована (при наличии базы данных, в которой лексемам уже приписаны те или иные семантические категории).
Пояснения по поводу порядка работы с текстом
Обработка исходного текста
Более чем вероятно, что вы обнаружите нужный вам текст на сайте библиотеки Мошкова. При этом необходимо иметь виду, что в большинстве случаев текст будет иметь следующий вид:

На рисунке видны следующие недостатки оформления текста, которые затруднят работу с ним:
- в конце строки имеется знак абзаца (¶),
- абзацный отступ выполнен несколькими пробелами,
- вместо тире стоит дефис или два дефиса,
- выравнивание текста по ширине выполнено введением дополнительных пробелов.
Если источник, найденный вами для анализа, свободен от указанных недостатков, пропустите следующий параграф, создайте в папке C:\Program Files\xmwin\bin текстовый файл в кодировке ANSI, сохраните его как text.txt и скопируйте в него содержимое своего текстового файла.
Для подготовки текста придется познакомиться с инструкцией, поставляемой совместно с программой “Графический интерфейс утилиты xMarkup. Руководство пользователя”. Следует создать текстовый файл, скопировать в него анализируемый текст, и указать этот файл в качестве исходного, апустить программу, указать в качестве файла правил обработки файл lib.par, включенный в состав архива, на вкладке “Результаты” выбрать “сохранять с префиксом xm$ в имени в исходную папку”. После выполнения преобразований необходимо проверить полученный файл с префиксом xm$, убедиться в отсутствии ошибок и переименовать его в text.txt для подготовки к загрузке в базу.
В начало
Преобразование исходного текста в набор таблиц
В состав скачиваемого архива входят три файла с правилами обработки, которые использует программа xMarkup, для преобразования исходного текста в набор таблиц. Все файлы правил обработки предусматривают работу с файлами в формате .txt с кодировкой ANSI и предназначены для преобразования информации в исходном файле в таблицы, записываемые в выходные текстовые файлы с разделителем в виде табуляции. Для указанной цели служат следующие файлы:
| Файл | Назначение | Вид получаемой таблицы |
| _para_num.par | нумерация абзацев в исходном тексте | <порядковый номер абзаца в тексте> – <текст абзаца> |
| _extr_para_sent_num.par | нумерация предложений в исходном тексте | <порядковый номер абзаца в тексте> – <порядковый номер предложения в тексте> – <текст предложения> |
_extr_sent.par
_extr_words.par | нумерация слов (словоупотреблений) в исходном тексте | – <порядковый номер слова в предложении> – <слово> |
Для выполнения всех преобразований сразу в состав архива также включен пакетный файл segment_text.bat. Для его выполнения необходимо, чтобы исходный текст был сохранен в кодировке ANSI как text.txt и находился в той же папке C:\Program Files\xmwin\bin. В результате выполнения файла segment_text.bat в той же папке появятся файлы _para.txt, _sent.txt, _words.txt, связь с которыми прописана в файле minicorpus.mdb. В состав пакетного файла segment_text.bat включены пояснения по поводу этапов работы с текстом, которые выводятся на экран командной строки при выполнении цикла (для возможности просмотра этих команд необходимо выбрать шрифт Lucida Console в огкне свойств командной строки).
В начало
Пояснения по поводу работы с парсером mystem
В состав скачиваемого архива включены два файла правил обработки mystem1.par, mystem2.par для их использования утилитой xMarkup, служебный файл mystem_add и пакетный файл lemmatize.bat, запускающий парсер mystem и необходимые преобразования. Работа с парсером предусматривает наличие входного файла in.txt, выгружаемого из minicorpus.mdb и содержащего перечень уникальных словоформ анализируемого текста с их числовыми идентификаторами. В фаийле in.txt словоформы располагаются в виде списка:
717<tab>белая
879<tab>бледно
После операции лемматизации, выполненной парсером, и преобразований, выполненных утилитой xMarkup, файл результатов out_n имеет вид
F1;F2;F3;F4;F5;F6;F7;F8;F9
717;белый=A;белая=S,фам,жен,од
879;бледный=A;бледно=ADV
В состав пакетного файла lemmatize.bat также включены пояснения по поводу этапов работы, которые выводятся на экран командной строки при выполнении цикла (для возможности просмотра этих команд также необходимо выбрать шрифт Lucida Console в огкне свойств командной строки).
В начало
Описание структуры базы данных minicorpus.mdb
Описание таблиц
В базе использованы таблицы следующих типов:
- таблицы связи с источниками данных — текстовыми файлами
- обновляемые таблицы, в которые записываются данные об анализируемом тексте
- перезаписываемые таблицы, служащие для обновления данных о частоте словоформ, лексем и количестве вариантов морфологического разбора
- таблицы-справочники, в которых хранятся текстовые метаданные, морфологические и семантические категории
Если не указано иное, описание полей таблиц находится внутри самих таблиц (для этого необходимо открыть соответствующую таблицу в режиме конструктора).
| Тип таблицы | Имя таблицы | Назначение |
|---|
| таблицы связи | _para | связь с файлом _para.txt, состоящим из двух колонок — номер абзаца и текст абзаца |
| _sent | связь с файлом _sent.txt, состоящим из трех колонок — номер абзаца, номер предложения в тексте и текст предложения |
| _word | связь с файлом _word.txt, состоящим из трех колонок — номер предложения, номер слова в предложении и слово (словоформа) |
| out_n | связь с файлом out_n.txt, содержащим результаты морфологического разбора, выполнного парсером mystem |
| обновляемые таблицы | t_paras | содержит абзацы исходного текста |
| t_sents | содержит предложения исходного текста |
| t_words | содержит слова (словоформы) исходного текста |
| words_plain | содержит уникальные (не допускающие повторений) словоформы исходного текста, служит для оптимизации токенизации и создания картотеки |
| word_lemm | хранение вариантов морфологического разбора словоформ с полем для указания правильного разбора |
| lemm_categ | хранение информации о грамматических и семантических характеристиках лексемм |
| перезаписываемые таблицы | word_repet | используется для подсчета частоты словоформ в тексте:- поле word2 — словоформа
- поле Повторы — количество употреблений
|
| lemm_freq | используется для подсчета частоты словоформ в тексте:- поле lemm — лексема с индексом ЧР
- поле lemm_freq — количество употреблений
|
| pos_var_qty | используется для подсчета количества вариантов морфологического разбора:- поле word1 — id словоформы из таблицы words_plain
- поле Повторы — количество употреблений
|
| таблицы-справочники | categ_1 | хранение списка семантических категорий (в поле categ_1, повторения не допускаются). |
| pos | хранение списка частей речи (в нотации, принятой в парсере mystem); поле pos — индекс части речи, в поле no отмечены незнаменательные части речи для того, чтобы в запросе lemm_categorization предлагались для анализа только слова знаменательных частей речи. |
В начало
Описание запросов
Каждый из запросов можно открыть в режиме “Конструктор” для просмотра таблиц и их полей, служащих источником данных для запроса.
| Тип запроса | Имя запроса | Назначение |
|---|
| запросы на удаление записей | clear_lemm_categ | удаление всех записей из таблицы lemm_categ |
| clear_t_paras | удаление всех записей из таблицы t_paras |
| clear_t_sents | удаление всех записей из таблицы t_sents |
| clear_t_words | удаление всех записей из таблицы t_words |
| clear_word_lemm | удаление всех записей из таблицы word_lemm |
| clear_words_plain | удаление всех записей из таблицы words_plain |
| запросы на добавление записей | add_paras | добавление данных из таблицы _para в таблицу t_paras |
| add_sents | добавление данных из таблицы _sent в таблицу t_sents |
| add_words | добавление данных из таблицы _word в таблицу t_words |
| add_words_plain | добавление уникальных словформ из таблицы t_words в таблицу words_plain |
| after_mystem_3 | добавление вариантов морфологического разбора в таблицу word_lemm для их анализа |
| after_mystem_4 | добавление слов с дефисом в таблицу word_lemm для их анализа |
| lemm_categ_add | добавление данных в таблицу lemm_categ |
| запрос на объединение | after_mystem_1 | После токенизации, выполненной парсером mystem, номеру-идентификатору словоформы приписаны в строку все варианты морфологического разбора. В целях дальнейшего анализа необходимо получить таблицу только из двух колонок — номер-идентификатор и вариант морфологического разбора. Для этого используется оператор UNION |
| запросы на выборку | after_mystem_2 | выбор непустых строк из запроса after_mystem_1 |
| lemm_categ_select | запрос-источник данных для добавления в таблицу lemm_categ |
| lemm_categorization | запрос для присвоения семантических категорий лексемам, источник данных для вкладки “Категоризация” |
| record_card | запрос для выбора необходимых параметров для формирования карточки слова; служит источником формирования подчиненной формы record_card на вкладке “Карточка слова” |
| record_card_source | запросы для выбора необходимых параметров для анализа сочетаемости слов |
| record_card_source_11 |
| record_card_two_words | запрос, результирующий выбор параметров для формирования карточки сочетаемости пар слов; служит источником формирования подчиненной формы record_card_two_words на вкладке “Сочетаемость” |
| record_set_1 | группировка лексем по категориям с возможностью просмотра контекстов употребления лексем, источник вкладки “Контексты по категориям” |
| tokenization | источник данных для принятия решения о правильном варианте морфологического разбора, источник данных для вкладки “Лемматизация” |
| word_sent | запрос, выделяющий конкретную словоформу в предложении верхним регистром букв |
| words_plain_for_mystem | источник данных для экспорта в файл in.txt для анализа парсером mystem |
| запросы на создание таблиц | after_mystem_5 | создание таблицы pos_var_qty, содержащей количество вариантов разбора словоформ |
| after_mystem_7 | создание таблицы word_repet, содержащей количество вариантов разбора словоформ |
| lemm_freq_create | создание таблицы lemm_freq |
| запросы на обновление | after_mystem_6 | добавление числа вариантов морфологического разбора в таблицу words_plain |
| after_mystem_8 | добавление частоты употреблений словоформы в таблицу words_plain |
| after_mystem_9 | добавление в таблицу t_words морфологического разбора словоформ, для которых парсер предложил только один вариант разбора |
| lemm_freq_update | обновление таблицы lemm_freq по результатам анализа правильности вариантов морфологического разбора |
| update_t_words_by_lemmas | вызывает обновление поля lemm_F таблицы t_words по результатам проверки морфологического разбора |
| update_tokenization | вызывает обновление поля checked таблицы words_plain по результатам проверки морфологического разбора |
В начало
Описание макросов
В базе использованы самые простые макросы — представляющие собой последовательный вызов тех или иных запросов. Макросы, с указанием запросов, которые они вызывают, и кнопок на форме MainForm, запускающих макросы, перечислены в таблице ниже. Пояснения по действиям, выполняемых макросом, не приводится, так как оно следует из названия кнопки. Запросы описаны в соответствующих разделах.
В начало
Описание интерфейса основной формы (MainForm) minicorpus.mdb
Под индикатором развертывания подразумевается кнопка “+” или “–” слева или справа от записи, служащая для развертывания или свертывания записей, сгруппированных относительно текущей записи.
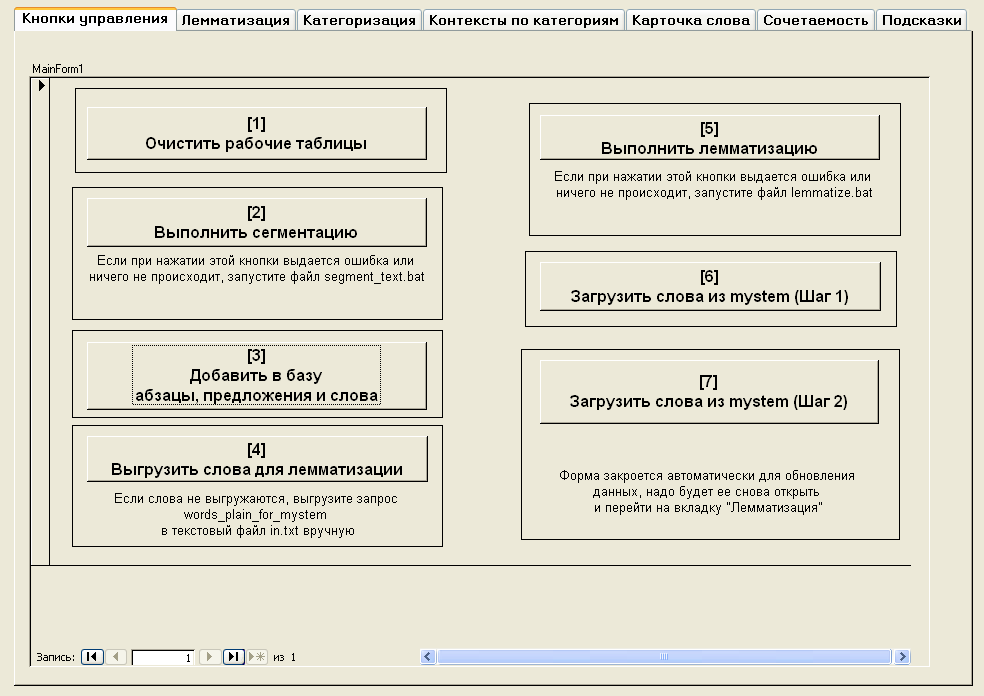
Вкладка Кнопки управления
На вкладке расположены кнопки, вызывающие выполнение запросов, макросов и пакетных файлов, необходимых для загрузки текста в БД и выполнения морфологического анализа. Если настройки MS Access на Вашем компьютере не позволяют выполнить какие-либо операции, необходимо следовать инструкциям внизу соответствующей кнопки.
В начало
Вкладка Лемматизация
Вкладка предназначена для токенизации тех словоформ, для которых парсер предложил более одного варианта морфологического разбора. Имеет окно с перечнем словоформ и две кнопки – Открыть как обычный запрос и Обновить результаты токенизации.
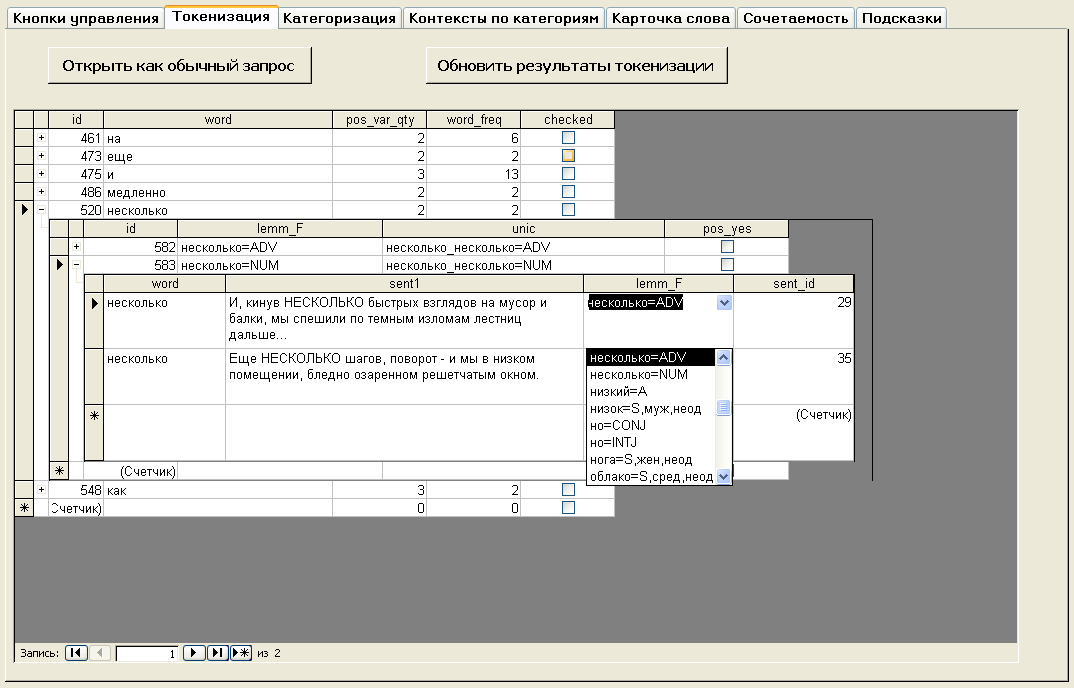
Окно с перечнем словоформ представляет собой таблицу со следующими колонками:
- word – словоформа
- pos_var_qty – количество вариантов морфологического разбора
- word_freq – частота употребления словоформы в тексте
Источником окна с перечнем словоформ служит запрос tokenization. При желании, можно изменить критерии отбора словоформ для токенизации. Для этого служит кнопка Открыть как обычный запрос. После того как запрос откроется, можно войти в режим конструктора и изменить условия отбора.
В правом столбце перечня словоформ имеется индикатор развертывания, после нажатия на который появляется вложенная таблица со следующими колонками:
- lemm_F – вариант морфологического разбора (вида “лексема=индекс части речи”; индексы частей речи перечислены на странице парсера mystem)
- pos_yes – поле, в котором следует отметить правильный вариант морфологического разбора
После нажатия на индикатор развертывания около любого из вариантов морфологического разбора появляется вложенная таблица с контекстами употребления словоформы. Вложенная таблица с контекстами имеет следующие колонки:
- context – предложение, в котором употреблена словоформа (словоформа в этом поле выделена верхним регистром; это не совсем удобно при просматривании контекстов употребления коротких слов, например, союза “и” – верхним регистром будут выделены все буквы “и” в предложении, однако при просмотре контекстов полнозначных слов длиной более четырех букв это неудобство пропадает)
- lemm_F – поле, в котором следует выбрать вариант морфологического разбора данного словоупотребления в конкретном предложении
Таблица с контекстами служит для следующих целей:
- просмотр контекстов для выбора правильного варианта токенизации
- указание правильного варианта токенизации для каждого словоупотребления в случае, если в пределах одного текста встречаются грамматические омонимы
Например, в тексте встретилось два глагола стекла и четыре существительных стекла. В этом случае во вложенной таблице контекстов достаточно указать правильный вариант разбора для глаголов (“стекать=V”), а в поле pos_yes поставить отметку напротив варианта разбора “стекло=S,муж,неод”. После нажатия кнопки Обновить результаты токенизации программа присвоит вариант разбора “стекло=S,муж,неод” всем неотмеченным употреблениям формы стекла.
В начало
Вкладка Категоризация
Предназначена для присвоения произвольных категорий лексемам, составляющим словник текста. Характер присваиваемых категорий зависит от целей исследования — это может быть гипероним, условное наименование ТГ, ЛСП, ФСП, интегральной семы / семантического множителя, концепта и т.д. При необходимости присвоения лексико-семантической информации всем лексемам текста можно ориентироваться на перечень лексико-семантических помет, представленных на странице, описывающей семантическую разметку НКРЯ. Вкладка имеет два окна и одну кнопку добавить леммы для анализа, на которую необходимо нажать после того, как всем необходимым для анализа лексемам была присвоена нужная морфологическая категория.
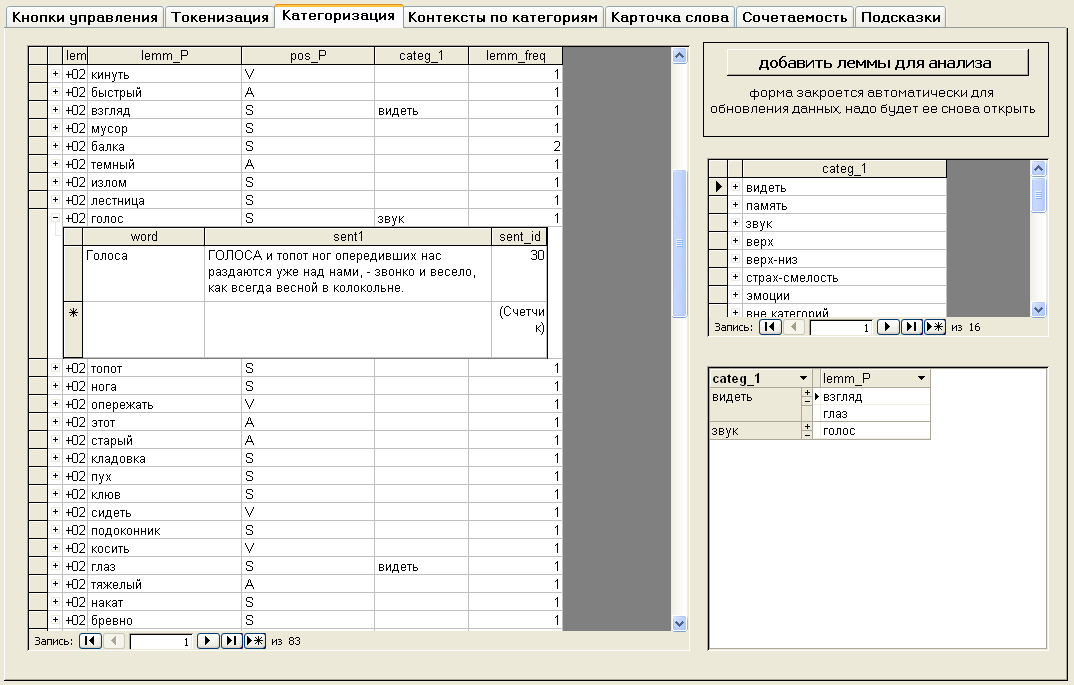
Окна вкладки:
- левое окно – перечень лексем (источником служит запрос lemm_categorization) со следующими колонками:
- lemm_P — лексема
- pos _P — часть речи
- categ_1 — семантическая категория
- lemm_freq — частота употребления всех словоформ лексемы в тексте
- крайний слева — столбец с индикатором развертывания, при нажатии на который появляется вложенная таблица с контекстами употребления словоформ лексемы.
- правое коно – перечень доступных категорий.
Если добавить новую категорию в пустую ячейку, то она отразится в списке выбора столбца categ_1 левого окна только после закрытия-открытия формы. Поэтому имеются ячейки с цифрами, в которые можно вводить имя новой категории — тогда во всплывающем списке она отобразится сразу.
В начало
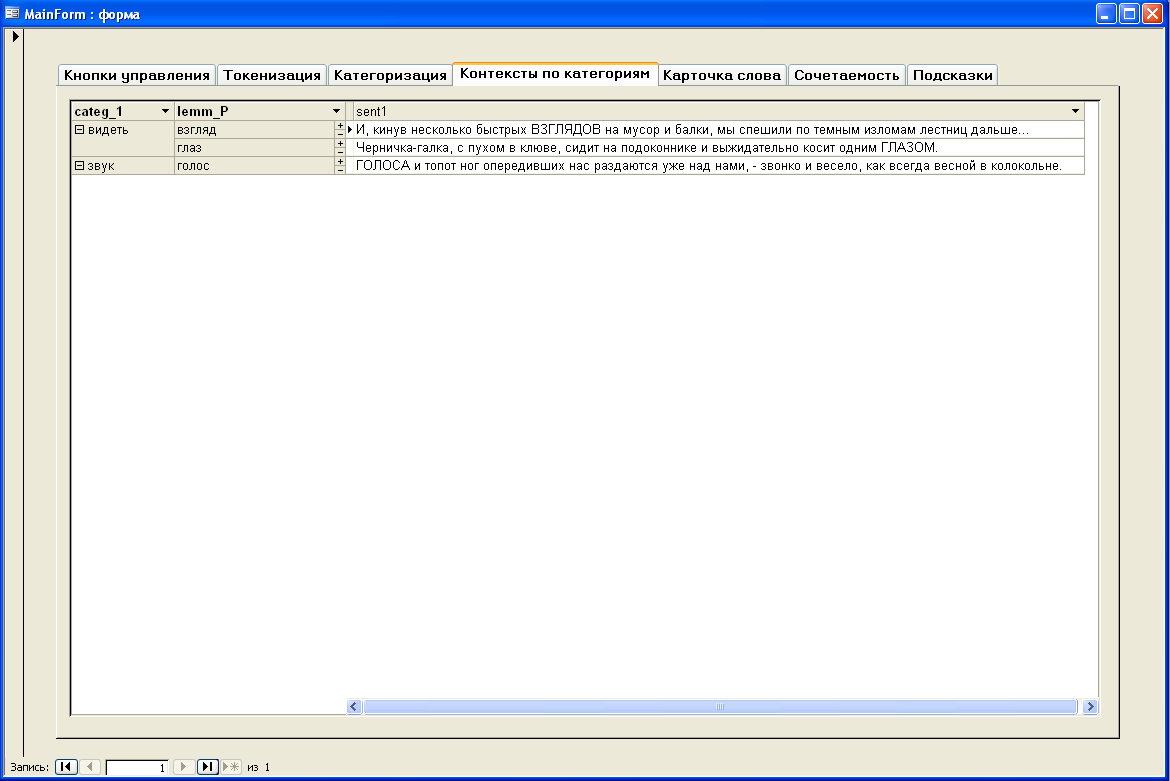
Вкладка Контексты по категориям
Вкладка позволяет увидеть выполненную группировку лексем по категориям с возможностью просмотра контекстов употребления лексем. Она может служить для верификации исследовательской гипотезы о распределении лексем той или иной категории в тексте, а также быть источником формирования рядов слов, соотнесенных по тому или иному критерию.
В начало
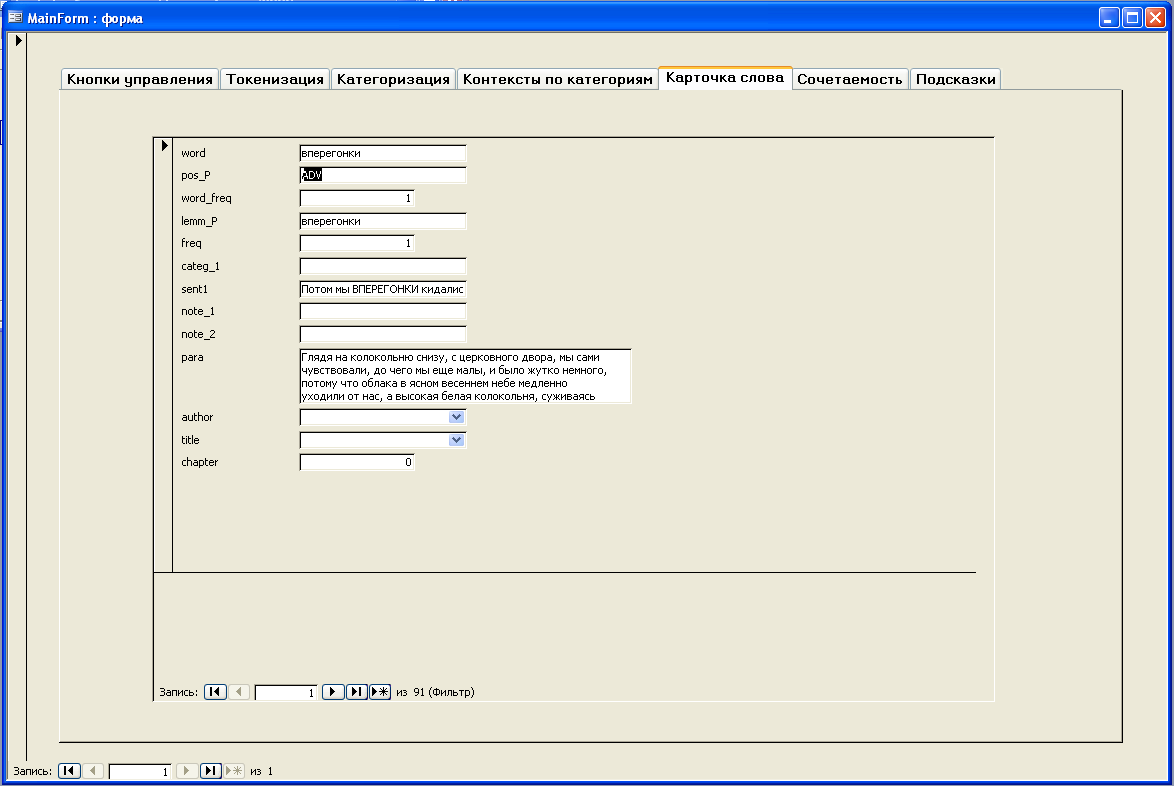
Вкладка Карточка слова
Вкладка сводит воедино всю хранящуюся в базе информацию о конкретном словоупотреблении
- контексты употребления с указанием количества употреблений;
- лемма с ее частеречной принадлежностью и приписанной ей семантической категорией;
- количество употреблений всех словоформ данной лексемы.
В начало
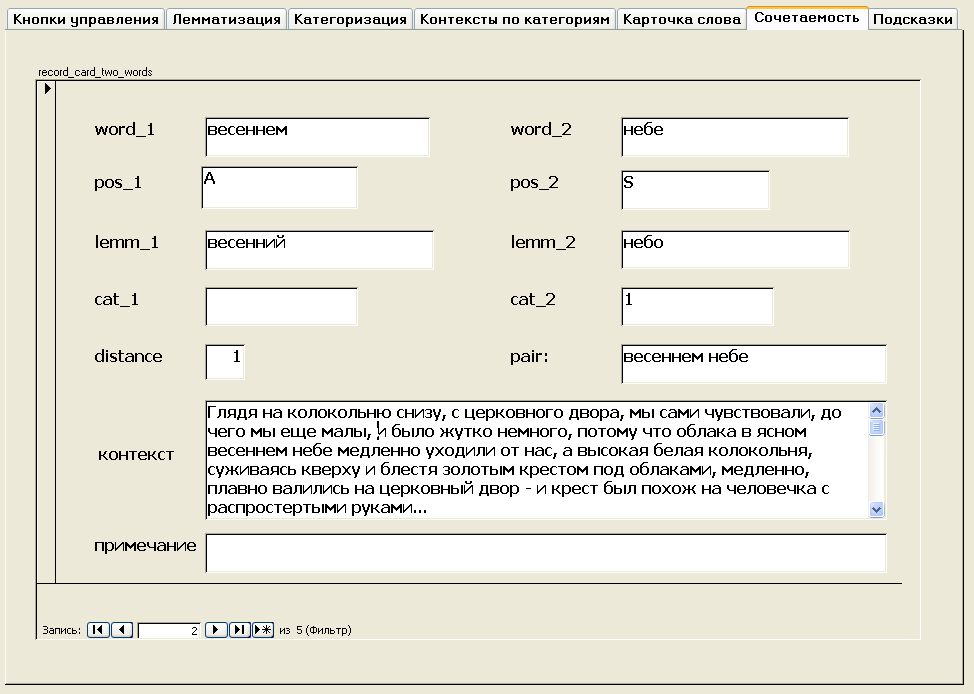
Вкладка Сочетаемость
Вкладка предназначена для моделирования поиска сочетаний слов в пределах предложений текста по нескольким категориям (ограниченно имитируя функциональность соответствующего поиска в НКРЯ). Использование стандартных средств фильтрации и сортировки позволяет искать пары слов по следующим параметрам (по отдельности или одновременно):
- лексема первого и / или второго слова;
- часть речи первого и / или второго слова;
- семантическая категория первого и / или второго слова;
- расстояние между словами в пределах предложения.
Вкладка Подсказки
Иногда на вкладках “Лемматизация” и “Категоризация” пропадает индикатор развертывания для отображения контекста. В этом случае необходимо выполнить действия, указанные на этой вкладке.
В начало